


Audio Classification using Deep Learning


Audio classification is a fascinating domain in deep learning that involves teaching algorithms to understand and categorize sound. Ever wondered how you are able to configure Siri or Alexa to operates solely on your command? It’s audio classification.
In this blog, I will take you through an audio classification and the steps involved.
How exactly does audio classification work?

Do machines have ears? 🧐
Unfortunately, not. Remember Convolutional Neural Networks, which allow us to process images, that is how we classify audio. In the first place, using signal processing, we extract distinct signals from the audio file and convert them to a group of signals with similar sample rate and frequencies. The resulting signals are converted to spectrograms.
What is a spectrogram?

A spectrogram is a visual representation of the frequencies of a signal over time. It's a graph that shows the strength of a signal at different frequencies and how it changes over time.
With the spectrogram, we can build and train a CNN to detect spectrograms of that kind as a specific audio or sound.
This is a brief run-down. Now, let us move into code implementation. We will train our audio classification model to detect the sound of capuchin birds.
We use tfio from tensorflow library to read audio files.
First, we import and install our dependencies such as tensorflow, matplotlib, etc and load our data

.Next, we convert audio to signals using the code below. In processing audio signal, there are some key words to take note of: channels and sample rate.
Channels represent the number of independent audio streams in a signal. It determines the spatial setup of the audio. It can be:
Mono(1 channel): A single channel of audio, used for simpler setups where spatial effects aren't necessary.
Stereo(2 channels): Two channels (left and right) to create a sense of spatial location.
Sample rate is the number of samples taken from the audio signal per second, measured in samples per second (Hz). determines the resolution of the audio signal. Common sample rates include:
· 44.1 kHz: Standard for CDs, captures frequencies up to 22.05 kHz (covers the human hearing range).
· 48 kHz: Used in professional audio and video production.
· 16 kHz or lower: Used for telecommunication or speech recognition.
Generally high sample rate and channel mean better audio; however, processing them can be quite difficult so to reduce the computation our model has to perform, we convert the sample rate down to 16kHz and reduce our channel to a single channel. This operation occurs in the below function.

In the next lines, we create tensorflow datasets to allow for easy fetching of our data and label our data.
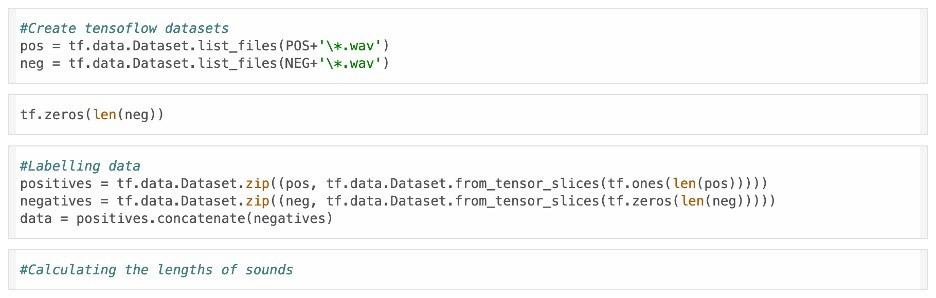
We then convert the signal to spectrograms which our CNN can learn to classify
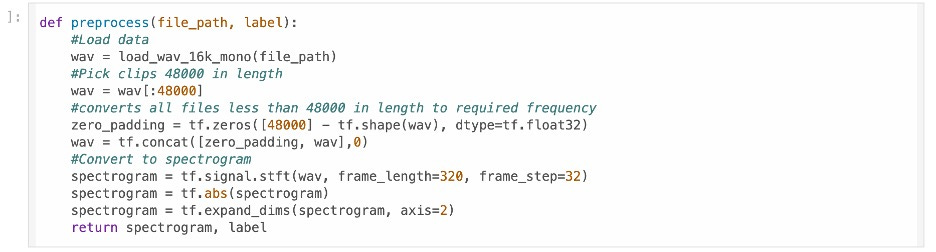
To allow for easy training, we preprocess our data. We randomize it by shuffling, separate it into batch sizes of 16 each and apply prefetching to prevent bottlenecking. We split our data into train and test samples.

We begin to build our model. We import the necessary dependencies and build our convolution neural network. We employ the Adam optimizer and Binary Cross Entropy for our loss function.
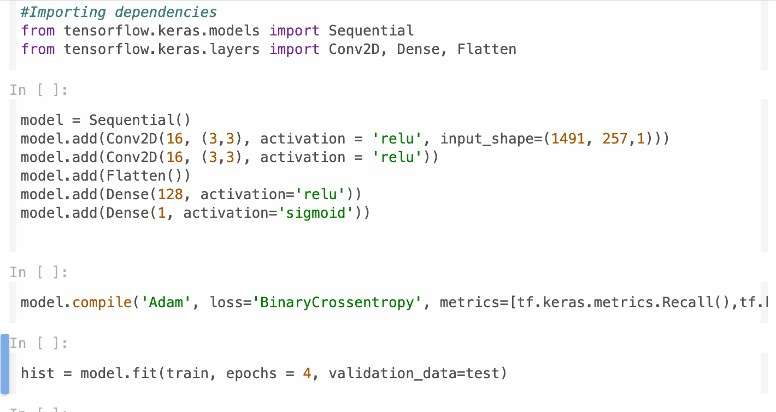
Our model is trained for some epochs, and we are done.
The model is able to detect with precision the sound of capuchin bird
Final Thoughts
Building an audio classification model has been quite interesting. It didn’t just require an understanding of deep learning but a fair grasp of signal processing concepts. Besides using the spectrograms, other methods can be used. A common and effective one is MFCC (Mel Frequency Cepstral Coefficients) which rather than produce images will produce feature vector which can be used to train a neural network to classify.
References:
[1]: Credit to https://www.youtube.com/@NicholasRenotte for helping with the notebook
[2]: https://github.com/Baah134/ Link to my Github